
卓序暖通设备行业网-专业生产加工、定做各种金属工艺品
国内金属工艺品加工专业厂家 全国服务电话 0551-66029451
全国服务电话 0551-66029451传真:+86-0551-66029451
手机:18010435401
邮箱:masizhuolannu@foxmail.com
地址:安徽省合肥市庐阳区蒙城北路与洪河路交口亚龙湾A座701室
目前,ChatGPT等生成式AI工具正在为整个行业带来全新的能力,而其模型所需的计算亦使性能、成本和能效成为众多企业关注的焦点。
随着生成式AI模型变得越来越大,在数据预处理到训练和推理等一系列复杂的AI负载功能上,能效成为推动生产力的关键因素。
开发人员需要一种灵活、开放、高能效和更可持续的解决方案,即“一次构建、随处部署”的方法,使各种形式的AI(包括生成式AI)都能充分发挥其潜力。
英特尔面向未来进行了大量投资,希望每个人都能利用这项技术,并能轻松进行大规模部署。同时,英特尔正与产业伙伴接洽,以支持一个基于信任、透明和多种选择的开放式AI生态系统。
近日,英特尔公布了自身在AI硬件和软件方面的最新进展,从这些信息,我们看到英特尔显然在极力加大自身在硬件创新的节奏,并在软件生态方面加大投入,让自身在AI加速计算方面有更多存在感。
以全面产品抓住新的市场机遇
如今,AI类工作负载成为主流,这对算力芯片提出了更高的要求。同时这也带了全新的市场空间。英特尔表示,五年后,数据中心芯片市场的规模将达到1100亿美元。
随着通用计算(主流为CPU)和加速计算(目前主流为GPU和专用加速器)的市场需求不断增长,到2027年,逻辑芯片的市场规模将超过400亿美元,AI芯片/加速器领域将大有可为。
根据WSTS数据,2020年全球人工智能芯片市场规模约为175亿美元。随着人工智能技术日趋成熟,数字化基础设施不断完善,人工智能商业化应用将加落地,推动AI芯片市场高速增长,预计2025年全球人工智能芯片市场规模将达到726亿美元。
不同种类别的AI计算芯片有各自突出的优势和适用的领域,贯穿AI训练与推理阶段。目前CPU在人工智能领域中的应用有限,主要受限于CPU在AI训练方面的计算能力不足。不过英特尔试图在改变业界对此的看法。
英特尔执行副总裁兼数据中心与人工智能事业部总经理Sandra Rivera 表示,“当谈论计算需求时,我们经常通过CPU的出货量来衡量市场规模。然而,插槽数量并不能完全反映芯片创新为市场带来的价值。如今,创新涉及多个维度,包括提高CPU内核的密度、使用芯片中的内置加速器,以及使用独立加速器等。”

例如第四代至强处理器是英特尔最具可持续性的数据中心处理器,有着更高的能效和节能效果。凭借英特尔AMX这样的内置加速器,在广泛的AI工作负载和使用案例中,推理和训练性能可提高10倍 ,同时其每瓦性能相较英特尔前代产品最多可提升14倍。
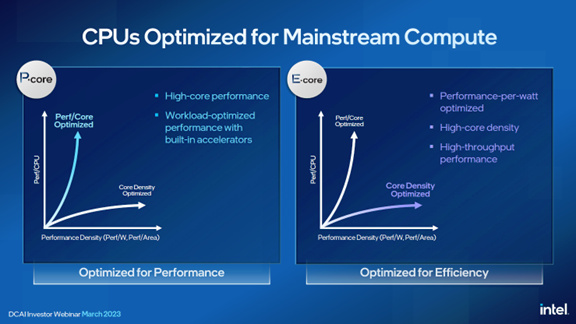
面向未来几代至强处理器,英特尔制定了全新的架构策略——即同时拥有基于性能核(P-core)和能效核(E-core)的双轨产品路线图,以将两个优化的平台整合为一个通用、定义行业发展的平台。该全新架构策略将更大限度地增强产品的每瓦性能和细分功能,从而全面增强英特尔在业界的整体竞争力。

据悉,Emerald Rapids是英特尔的下一款性能核(P-core)产品,被正式称为第五代英特尔至强可扩展处理器。目前正在向客户提供样品,并计划于2023年第四季度进行交付,量产验证正在进行中。

Sierra Forest是第一款能效核(E-core)处理器,计划在2024年上半年上市。Sierra Forest是第一款采用即将推出的Intel 3制程工艺的CPU。Sierra Forest为云优化的工作负载而设计,将通过优化的每瓦性能、高内核密度,以及高吞吐量性能针对能效进行优化。

Granite Rapids在2024年将紧随Sierra Forest之后发布。英特尔首次公开表示,将在Sierra Forest之后开发后续产品Clearwater Forest,继续实施其能效核路线图。Clearwater Forest将于2025年上市,采用Intel 18A制程工艺制造。英特尔计划在该节点实现制程工艺领先——这也将是公司四年内推进五个制程节点战略的高潮。

除了CPU产品,英特尔的产品组合涵盖GPU、FPGA、ASIC、独立AI芯片等,以全面的产品帮助客户应对AI挑战。
AI加速看得见
硬件的加速有赖于软件的优化,英特尔在软件方面也加大投入,比如我们熟知的oneAPI和OpenVINO等。
Sandra Rivera表示,“客户希望他们的AI工作负载具有可移植性。他们希望通过一次构建,即可将AI部署到任何地方。随着我们继续为AI工作负载提供异构架构,它们的大规模部署将需要方便开发人员编程的软件,以及一个充满活力、开放、安全的生态系统。”
近日,顶级机器学习开源库Hugging Face分享性能结果,展示了Habana Gaudi2 AI硬件加速器针对1760亿参数大模型卓越的运行推理速度。同时,该结果亦展现了在Gaudi2服务器上运行主流计算机视觉工作负载时的能效优势。
Gaudi2与第一代Gaudi构建在相同的高效架构上,可助力大规模工作负载的性能和效率达到全新高度,并在运行AI工作负载时展现出强大的能效优势。
英特尔公司副总裁兼至强产品部总经理Lisa Spelman表示,生成式AI模型Stable Diffusion在内置英特尔高级矩阵扩展(英特尔AMX)的第四代英特尔至强可扩展处理器上运行的平均速度提高了3.8倍。这种加速是在不更改任何代码的情况下实现的。此外,通过使用英特尔Extension for PyTorch with Bfloat16(一种用于机器学习的自定义格式),自动混合精度可以再提速一倍,并将延迟减少到5秒——比初始基线32秒快了近6.5倍。
OpenVINO进一步加速了Stable Diffusion推理。结合使用第四代至强CPU,它的速度几乎比第三代英特尔至强可扩展CPU提高了2.7倍。Optimum Intel是OpenVINO支持的一个工具,用于加速英特尔架构上的端到端管道,它将平均延迟再降低3.5倍,总共降低近10倍。
英特尔首席技术官兼软件与技术集团负责人Greg Lavender表示,“对于CUDA,大家越来越期待开放的、多供应商、多架构的替代方案。我们认为,该行业将受益于标准化的编程语言,让每个人都可以为其做出贡献,并展开广泛的合作,而不是受限于某个特定的供应商,与此同时,亦可以根据成员的以及一些共性需求寻求有机的发展。”英特尔为SYCL(一种基于C++的开放编程模型)做出了很多贡献,并收购了Codeplay Software(SYCL语言和社区的领导者)。SYCL包含于oneAPI中,因此客户可以跨多个供应商的CPU、GPU和加速器进行编程和编译。上游软件优化方面的其他工作包括针对PyTorch 2.0和TensorFlow 2.9的优化,以及与Hugging Face的合作,均可在英特尔至强处理器和Gaudi 2的帮助下进行训练、调优和预测。
面向AI的开放加速计算
英特尔致力于AI的真正民主化和可持续性,这将使人们能够通过开放的生态系统更广泛地从该技术,以及生成式AI技术中获益。
英特尔技术是AI硬件的基石,从至强处理器上的数据准备及管理,到中、小型训练与推理,同时,越来越多的大模型训练和推理正在使用英特尔GPU和加速器。
借助英特尔的AI软件套件,开发者可以使用自己选择的AI工具,提高生产力并加快AI开发速度。该套件已经针对400多个机器学习和深度学习AI模型进行了验证,涵盖所有商业细分领域最常见的AI应用场景。
基于开放方法和异构计算的生成式AI使其更容易获得,并更经济地部署最优的解决方案。开放生态系统允许开发人员在优先考虑功耗、价格和性能的同时,随时随地构建和部署AI,从而释放生成式AI的力量。
英特尔正在积极采取措施,并通过优化主流的开源框架、库和工具来实现出色的硬件性能,同时消除复杂性,来确保自身是实现生成式AI的明智选择。
一个开放的生态系统让开发人员能够利用英特尔对流行开源框架、库和工具的优化,来构建和部署AI。英特尔AI智能硬件加速器以及第四代英特尔至强可扩展处理器的内置加速器提升了性能和每瓦性能,以满足生成式AI对性能、价格和可持续性的需求。
